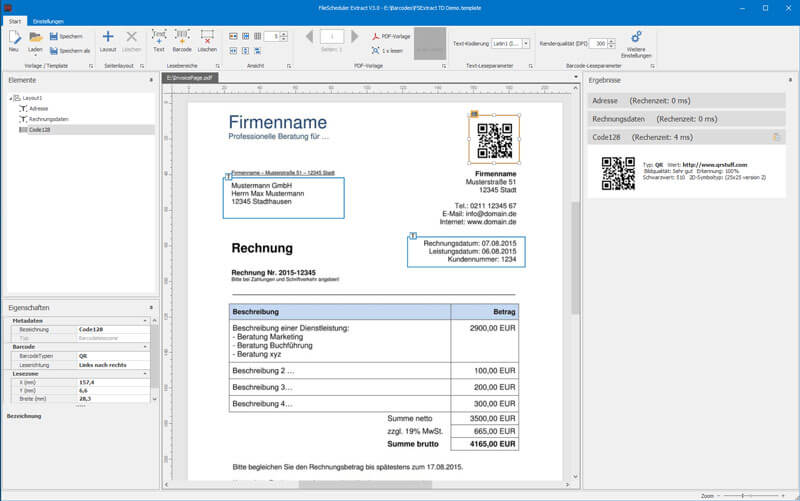
Klicken Sie auf die einzelnen Register, um Details anzuzeigen.
Oftmals enthalten die von Scannern erzeugten PDF-Dokumente nur die „Fotos“ der gescannten Dokumentenseiten.
Die
Textlesung des FS Extract Moduls setzt voraus, daß die PDF-Dokumente Textinformationen enthalten.
Für gescannte PDF-Dokumente, die nur Bilder enthalten, kann die Textlesung des FS Extract Moduls nicht genutzt werden.
Gescannte Dokumente, die einen OCR-Prozess durchlaufen haben, bei dem die mittels OCR gelesenen Textinhalte hinzugefügt wurden, können in der Regel mit dem FS Extract Modul verarbeitet werden.
Hinweis: Sie können einfach prüfen, ob die Textlesung ihrer gescannten PDFs möglich ist. Öffnen Sie die gescannte PDF-Datei in einem PDF-Viewer und versuchen Sie mit Hilfe eines Text-Auswahlwerkzeugs Worte oder Sätze zu markieren.
Wenn das gelingt, kann der Text auch von FS Extract gelesen werden. Wenn Sie sich nicht sicher sind, senden Sie Ihre Datei einfach zur Prüfung an
Info@dev4print.com. Selbstverständlich werden Ihre Daten absolut vertraulich behandelt.
Im Gegensatz zur Textlesung kann die
Barcodelesung auch mit Fotos / eingescannten Bildern und Dokumenten (PDF, TIF, PNG, JPG, BMP) arbeiten. So kann die FS Extract Barcodelesung auch mit PDFs genutzt werden, die durch
Einscannen erstellt wurden. So können beispielsweise Papierordner, deren Register oder auch Pläne in einzelnen Dokumenten eingescannten wurden, automatisiert wieder zu einem Gesamt-PDF zusammengesetzt werden.
Lizenzierung des FileScheduler Extract – Moduls
Das FS Extract – Modul besteht aus einer optionalen Lizenz für den FS Extract Designer und einer Lizenz-Erweiterung für die zugehörige FileScheduler Workflows Installation.
Für jeden Rechner (bzw. virtuelle Maschine) auf dem die FS Extract – Funktionalität in automatisierten FileScheduler Workflows genutzt werden soll, wird eine FS Extract Modul – Lizenz benötigt.
Wenn Sie auch mit dem optionalen FS Extract Designer arbeiten möchten, benötigen Sie eine FS Extract Designer Lizenz für jeden Rechner (bzw. virtuelle Maschine), auf dem der FS Extract Designer installiert werden soll.
Die Lizenz ist damit
- unabhängig von der Anzahl der Workflows, die die Extract Funktionen des Moduls nutzen
- unabhängig vom verarbeiteten Datenvolumen (z.B. Seitenanzahl, PDF-Anzahl, etc.)