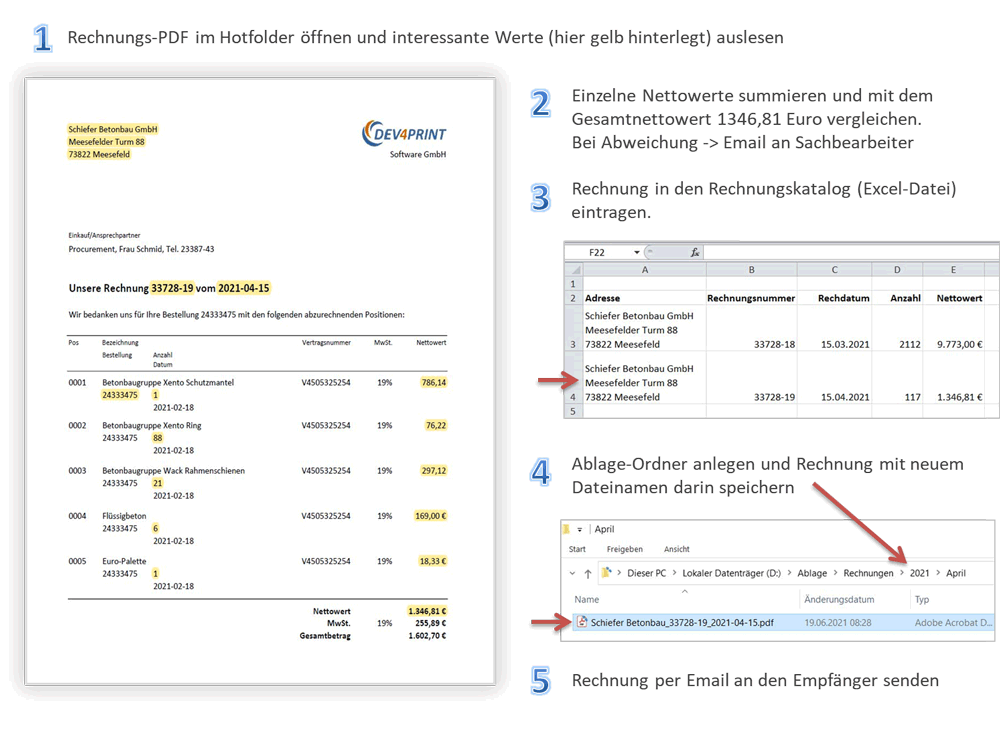
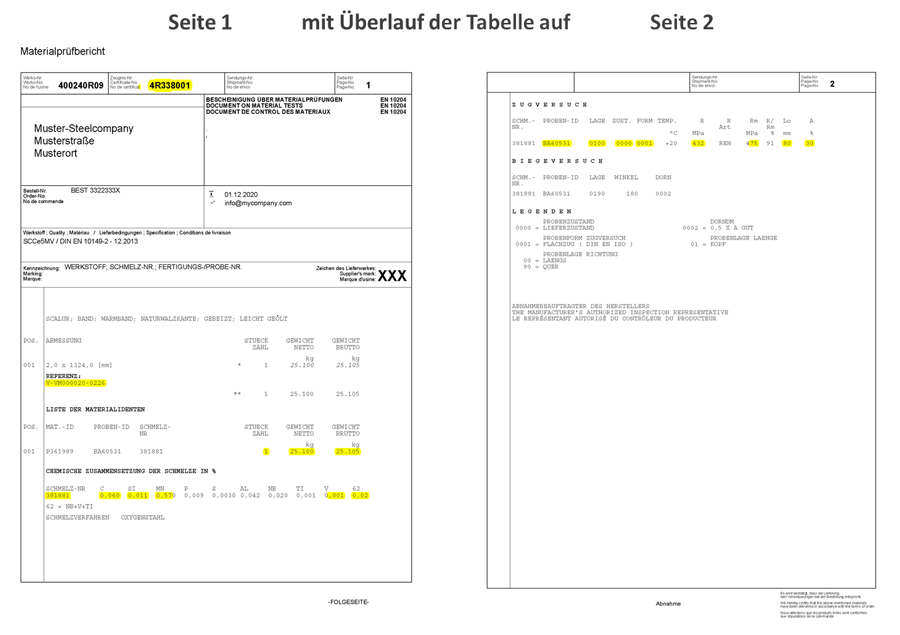
Mit dem FileScheduler Workflows Server und dem Erweiterungsmodul "FS Extract", können vollautomatisierte Daten-Extraktions-Workflows erstellt werden.
Der von Ihnen gewünschte Ablauf kann wie immer genau nach Ihrer Anforderungen als sogenannte Workflow-App (= FileScheduler Workflow) implementiert werden. Neben Informationen aus dem PDF-Seitentext können auch Daten/Werte aus Barcodes (mehr als 45 Barcodetypen und Subtypen), Inhalte aus dem PDF-Dateinamen und aus den PDF-Metadaten ausgelesen und im Workflow verarbeitet werden.
FileScheduler Extract Lösung werden aufgrund ihrer hohen Performance und Verarbeitungssicherheit überwiegend in der Industrie verwendet, wo ein hoher Automatisierungsgrad von Prozessen in Verbindung mit einer hohen Zuverlässigkeit bei der Verarbeitung der Daten benötigt wird.
Auslesen der Daten mittels OCR?
Das "FS Extract"-Modul ermöglicht das hochperformante Auslesen von Daten direkt aus dem im PDF enthaltenen Seitentext. Dieses Verfahren ist um ein Vielfaches performanter und zuverlässiger als Verfahren, die auf OCR (optischer Zeichenerkennung) basieren.
Falls Sie Daten aus eingescannten Dokumenten (=Bild-PDFs) verarbeiten möchten, muß das Dokument zuvor einen OCR-Prozess durchlaufen, um die benötigten Seitentexte zu erzeugen und die Texte in das PDF zu integrieren. Mittels OCR erzeugen Sie aus dem Bild-PDF ein "durchsuchbares PDF-Dokument", das dann vom FileScheduler Extract-Workflow verarbeitet werden kann.
Sie können dazu eine bereits in Ihrem Unternehmen vorhandene OCR-Software nutzen oder die OCR-Option des FS Extract Moduls nutzen.
Dokumente aus der Eingangspost oder Ausgangspost?
Natürlich kann Ihr FileScheduler Extract -Workflow PDF-Dokumente aus der Eingangspost und der Ausgangspost verarbeiten.
"Eingangspost" bezieht sich dabei in der Regel auf die von extern eingehende Dokumente, also PDF-Dateien,
- die zuvor durch das Einscannen von Brief-Post entstanden sind
- die Ihr Workflow zuvor aus eingehenden Emails extrahiert (PDF-Dateianlagen oder ZIP-Dateianlagen) hat
- die Ihr Workflow zuvor mittels HTTPS oder FTPS/SFTP von einem externen Server heruntergeladen hat
- die zuvor in einer internen Verzeichnisstruktur (z.B. Netzlaufwerk) oder Hotfoldern gespeichert wurden
"Ausgangspost" bezieht sich üblicherweise auf Dokumente, die in Ihrem Unternehmen verlassen werden und im Unternehmen
- durch Drucken in eine PDF -Datei mittels PDF-Druckertreiber entstanden sind
- durch Speichern als PDF (z.B. MS Word) entstanden sind
- durch Konvertierung in das PDF-Format entstanden sind
- in einer Datenbank oder einem Dokumenten Management System (DMS) gespeichert vorliegen
Um spezielle Informationen unabhängig von der Position sicher aus Fließtexten oder aus Tabellen auszulesen, werden im Extract-Workflow Methoden zur Erkennung von Daten-Mustern verwendet. So können auch Daten aus mehrseitigen PDF-Dokumente mit seitenübergreifenden Tabellen zuverlässig ausgelesen werden.
Alle ausgelesenen Daten können im Workflow beliebig genutzt werden. Sie können beispielsweise als Basis für Berechnungen dienen, in MS Excel--Tabellen oder andere Dateiformate/Datenbanken ausgegeben werden, in personalisierten Email-Texten eingesetzt werden, einfach nur protokolliert werden oder dazu dienen, andere PDF-Dokumente in Ordnern zu finden, um sie an das Hauptdokument anzuhängen. Hier gibt es keine Grenzen!
Einsatzbereiche
Es gibt zahlreiche Einsatzbereiche für FileScheduler Extract Workflows. Hier einige Beispiele:
- Posteingangsverarbeitung: Auslesen von Daten aus PDF-Anlagen eingehender Emails sowie aus eingescannten PDF-Dokumenten. Verarbeitung oder Verteilung der Dokumenten nach Ihrem vorgegeben Regelwerk. Beispielsweise Prüfung der enthaltenen Daten und Verteilung per Email an zuständige Sachbearbeiter oder Import der Dokumente in Ihre Businessanwendung/DMS.
- Überprüfung von erstellten Rechnungen, Lieferscheinen etc. vor dem elektronischen Versand.
- Ausführen des elektronischen Versands (Email) auf Basis von Daten, die im Dokument enthalten sind.
- Automatische Verarbeitung von eingehenden Dokumenten: Automatische Extraktion der an die Email angehängten Dateianlagen. Ermittlung des Dokumententyps (z.B. Rechnung, Lieferschein) der Anlagen auf Basis von Daten im PDF. Automatische individuelle Verarbeitung der Dokumente je nach Dokumententyp, z.B. automatische Weiterleitung an zuständige Mitarbeiter/-innen.
- Portooptimierung im Briefdruck: Auslesen von Adressen, Vergleichen von Adressen und Zusammenfassen von Dokumenten mit gleicher Empfangs-Adresse in einer Briefsendung / Kuvert.
- Überprüfung von Adressen: Auslesen von Adressen, Analyse der Adressen-Struktur und Prüfung auf Fehler. Abgleich der Adressen mit einer Datenbank.
- Intelligente Serienbrieftrennung: Erkennung von Einzeldokumenten im PDF-Serienbrief auf Basis von Daten auf den PDF-Seiten und Export der einzelne Dokumente als einzelne PDFs.
- Intelligentes Aufteilen von großen Dokumenten im Druckbereich, falls die Nachverarbeitung nur bestimmte Dokumentengrößen zulässt.
Automatisches Trennen der Dokumente beispielsweise am Kapitelanfang.
Was benötige ich für eine automatisierte Lösung?
Falls Sie einen automatisierten PDF-Datenextraktions-Prozess nutzen möchten, benötigen Sie
- eine Lizenz des FileScheduler Workflows Servers inkl. Extract Modul
- eine Workflow-App, in der Ihr Datenextraktions-Prozess implementiert ist
Kunden, die bereits einen FileScheduler Workflows Server nutzen, benötigen ggfs. nur das FileScheduler Extract Modul und die Workflow-App.